
C7: Computer Science as a Discipline
Having surveyed the relationships of computer science with other disciplines, it remains to answer the basic questions: What is the central core of the subject? What is it that distinguishes it from the separate subjects with which it is related? What is the linking thread which gathers these disparate branches into a single discipline? My answer to these questions is simple — it is the art of programming a computer. It is the art of designing efficient and elegant methods of getting a computer to solve problems, theoretical or practical, small or large, simple or complex. It is the art of translating this design into an effective and accurate computer program. — C.A.R Hoare
Most traditional sciences, such as biology and chemistry, trace their origins back hundreds or even thousands of years. As electronic computers were not introduced until the 1940s, computer science is clearly a much newer discipline. Nonetheless, computers and related technology have made an astounding impact on our society in this short period of time. This chapter presents an overview of computer science as a discipline, emphasizing its common themes as well as its breadth.
As you will learn, computer science comprises much more than just the study of computers. It encompasses all aspects of computation, from the design and analysis of algorithms to the construction of computers for carrying out those algorithms. The jobs performed by computer scientists are as varied as computer science itself, and this chapter examines the roles played by computational theorists, programmers, systems architects, and knowledge engineers, among others. To further your understanding of this diverse discipline, we delve into specific computer science subdisciplines and conclude with a discussion of ethical conduct within the computing profession.
Computer "Science"
Although governments and industry began embracing computer technology as early as the 1940s, the scientific community was slower to acknowledge computer science's importance. Most colleges and universities did not even recognize computer science as a discipline until the 1970s or 1980s. Many people still argue that computer science is not a science in the same sense that biology and chemistry are. In reality, computer science has much in common with the natural sciences, but it is also closely related to other disciplines, such as engineering and mathematics. This interdisciplinary nature has made computer science a difficult discipline to classify. Biology can be neatly described as the study of life, whereas chemistry can be defined as the study of chemicals and their interactions. Is computer science, as its name suggests, simply the study of computers?
Although computers are the most visible feature of computer science, it would be inaccurate to characterize the discipline as dealing only with machinery. A more inclusive definition would be that computer science is the study of computation. The term "computation" denotes more than just machinery — it encompasses all aspects of problem solving. This includes the design and analysis algorithms, the formalization of algorithms as programs, and the development of computational devices for executing those programs. The computer science discipline also addresses more theoretical questions, such as those surrounding the power and limitations of algorithms and computational models.
Whether this combination of problem solving, engineering, and theory constitutes a "science" is a matter of interpretation. Some define "science" as a rigorous approach to understanding complex phenomena and solving problems, utilizing the scientific method (Chapter C5). Using this definition, we can classify many activities performed by computer scientists as "science." For example, verifying the behavior of an algorithm requires forming hypotheses, testing those hypotheses (either through experimentation or mathematical analysis), and then revising the algorithm in response to the results. The development of complex hardware and software systems also adheres to this same rigorous, experimental approach — when applied to projects involving millions of transistors or thousands of lines of code, the scientific method is merely implemented on a much larger scale.
Artificial Science
What sets computer science apart from the natural sciences is the type of systems being studied. All natural sciences, as well as many social sciences, are concerned with examining complex, naturally occurring phenomena. These sciences work within the confines of innate laws that define the way matter behaves, the way chemicals react, the way life evolves, and even the way people interact. Experiments in physics, chemistry, biology, and psychology strive to understand natural occurrences and extract the underlying laws that control behavior. By contrast, the systems that computer scientists investigate are largely artificial. Programs, computers, and computational models are designed and constructed by people. When a computer scientist analyzes the behavior of a program executing on a particular computer, the phenomena being studied are defined within the artificial world of that machine. Likewise, by devising new computers or other computational models, computer scientists can create their own artificial laws to govern how systems behave. This distinction was effectively summarized by artificial intelligence pioneer Herbert Simon (1916-2001), who coined the phrase "artificial science" to distinguish computer science from the "natural sciences."
It is interesting to note that the European name for the computing discipline, Informatics, bypasses the question of whether the discipline is a science or not. Instead, the name emphasizes the importance of information processing within the discipline, independent of the machinery used.
✔ QUICK-CHECK 7.1: TRUE or FALSE? The discipline of computer science is concerned solely with the design and development of computational machines.
✔ QUICK-CHECK 7.2: TRUE or FALSE? Unlike in the natural sciences (such as physics and biology), the systems that computer scientists investigate are largely artificial (e.g., programs, computers, computation models).
Computer Science Themes
Because computation encompasses so many different types of activities, the work conducted by computer scientists is often difficult to classify. However, there are three recurring themes that define the discipline: hardware, software, and theory (FIGURE 1). Some computer scientists focus primarily on hardware, designing and building computers and related infrastructure. Others concern themselves with the process of composing software and encoding algorithms that can be executed on computers. Still others attack computation from a theoretical standpoint, striving to understand the foundations of the discipline. Although it is possible to find computer scientists whose expertise is exclusive to one of these areas, most activities involve a combination of all three.
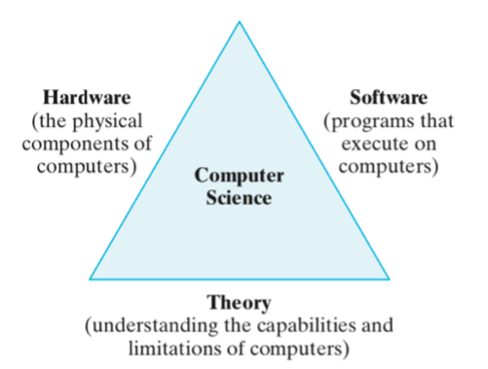
FIGURE 1. Main themes of computer science.
Hardware
As we saw in Chapter C1, the term "hardware" refers to the physical components of a computer and its supporting devices. The design of most modern computers is based on the von Neumann architecture, which consists of a CPU, memory, and input/output devices. In combination, these three components form a general-purpose machine that can store and execute programs for accomplishing various tasks.
Although most computers are built according to this basic architecture, ongoing research and development projects aim to improve the design and organization of hardware. For example, computer scientists involved in circuit design and microchip manufacturing must draw on expertise from chemistry, physics, and mechanical engineering to squeeze billions of transistors onto dime-sized microchips. Systems architects, on the other hand, study different ways of connecting components to increase computational throughput (i.e., the amount of work that can be completed in a given time). As the Internet has grown in popularity, many hardware specialists have turned their attention to networking, creating new ways for separate computers to share information and work together.
Software
Whereas hardware consists of machinery for performing computations, "software" refers to the programs that execute on computers. Most people in the computer industry work on the software side, holding positions such as programmer, systems analyst, software engineer, or Web developer. According to the U.S. Bureau of Labor and Statistics, the software industry is one of the fastest-growing and highest-paying facets of the U.S. economy.
Software can be divided into three basic categories according to each application's purpose and intended audience. Systems software includes programs that directly control the execution of hardware components. For example, an operating system includes systems software for managing files and directories, linking programs with hardware devices such as printers and scanners, and processing user inputs such as keystrokes and mouse clicks. The term development software refers to programs that are used as tools in the development of other programs. Microsoft .NET, Oracle Java Development Kit, and Phoenix Frameworks Phoenix are examples of development environments for creating, testing, and executing programs using a variety of languages (such as C++, Java and JavaScript). The applications software category encompasses all other programs, which perform a wide variety of complex tasks. Examples include Web browsers such as Google Chrome and Mozilla Firefox, word processors such as Word and Corel WordPerfect, presentation tools such as Microsoft PowerPoint and Adobe FrameMaker, editors such as Microsoft NotePad and GNU emacs, and games such as Google Solitaire and Epic Games Fortnite.
✔ QUICK-CHECK 7.3: TRUE or FALSE? The term applications software refers to any software tool that is used to develop other software.
Theory
Just as certain computer scientists study algorithms but never write a program, other experts may never even touch a computer. This is because computer science is also concerned with the study of computational methods, in addition to the more practical themes of hardware and software. Theoretical computer scientists, whose work is closely related to mathematics and formal logic, examine different models of computation and strive to understand the capabilities of algorithms and computers. It may surprise you to learn that some of computer science's key theoretical results were formulated years before the development of electronic computers. For example, in 1930, Alan Turing (1912-1954) designed an abstract computational machine now known as a Turing machine. A Turing machine describes a simple computational device with a paper tape on which characters can be written (I/O), a processor that can read and write characters and move back and forth along the tape (CPU), and space to store a single number defining the state of the device (memory). It is programmable in that you can specify a finite set of rules to describe the processor's behavior.
FIGURE 2 provides an interactive visualization of a Turing machine. On the left are the components of the Turing machine: the tape of characters, the processor (initially pointing to the first cell of the tape), and the state (initially 0). On the right is a simple program that can be executed on the machine. This program determines if the number of a's on the tape, up to the first dash, is even (in which case it writes 'E' on the tape and halts) or odd (in which case it writes 'O' on the tape and halts). Note that the program instruction that matches the current tape contents and state is highlighted in red. Initially, the processor is pointing at the first cell, which contains an 'a', and the state is 0, so the matching instruction is highlighted. Clicking on the "Execute Instruction" button will carry out the prescribed actions, such as writing on the tape, moving the processor or changing the state.
| TURING MACHINE | PROGRAM | |||||||||||||||||||||||||
|
|
FIGURE 2. Interactive Turing machine visualizer.
✔ QUICK-CHECK 7.4: The tape in the visualizer currently holds 7 a's. Repeatedly click on the Execute Instruction button to see how the Turing machine changes as the program instructions are executed. Since there is an odd number of a's, the processor should eventually write 'O' on the tape and halt (since there is no instruction corresponding to state 2). Confirm that this is the case.
✔ QUICK-CHECK 7.5: Click on the Reset button to reset the visualizer. Then, change the last 'a' on the tape (cell 7) to '-'. Repeatedly click on the Execute Instruction button to observe the machine's behavior. Since there is an even number of a's, the processor should eventually write 'E' on the tape and halt. Confirm that this is the case.
Although Turing machines might seem simplistic, theoretical analysis has proven them to be as powerful as today's computers. That is, any computation that can be programmed and performed using a modern computer can also be programmed and performed using a Turing machine. Of course, the equivalent Turing machine program might be much more complex and require a much larger number of steps; however, the Turing machine would eventually complete the task. The advantage of a simple model such as the Turing machine is that it provides a manageable tool for studying computation. In fact, Turing was able to use the Turing machine model of computation to prove a rather astounding result: there exist problems whose solutions cannot be computed. In other words, he showed that certain problems are not solvable using algorithms or any computing device.
The most famous noncomputable problem involves a scenario you may have encountered before. Sometimes, a piece of software may appear to hang, freezing in the middle of some task and failing to respond to any inputs. It could be a temporary glitch caused by other software or hardware issues that will eventually resolve itself and allow the software to complete its task. Or it could be a serious problem from which the software will never recover. How are you to know whether the software would eventually halt on its own or whether you need to interrupt and restart it? Turing showed in 1930 that, in general, there is no way to know for sure. In programming terminology, the Halting Problem states that you can't write a program that determines in all cases whether another program will terminate.
In general, theoretical computer scientist attempt to understand computation at a level that is independent of the machine architecture. This enables the discipline to provide a strong foundation for developing new algorithms and computers.
✔ QUICK-CHECK 7.6: TRUE or FALSE? Theoretical computer scientists have proven that any problem that can be stated clearly is solvable via an algorithm.
Subdisciplines of Computer Science
In his classic 1999 description of the discipline, Computer Science: The Discipline, Peter J. Denning (1942-) identified 12 major subdisciplines of computer science. Each subdiscipline constitutes a unique viewpoint and approach to computation, many of which have close ties to other disciplines, such as physics, psychology, and biology. However, the common themes of computer science — hardware, software, and theory — influence every subdiscipline. The following sections examine four of computer science's most visible subdisciplines: Algorithms, Architecture, Software Engineering, and Artificial Intelligence. Although it is impossible to include a complete description of these subdisciplines in such a short space, these sections summarize the key ideas that define the subdisciplines and provide representative examples from each.
Algorithms
The Algorithms subdiscipline involves developing, analyzing, and implementing algorithms for solving problems. As algorithms are fundamental to all computer science, researchers in this subdiscipline can approach the topic from various perspectives. A theoretical computer scientist might be concerned with analyzing the characteristics, efficiency, and limitations of various algorithms. This type of work is relevant, because examining which types of algorithms are best suited to certain tasks can lead to more effective problem solving. As programs are simply implementations of algorithms, software development is driven by an understanding and mastery of algorithms. To develop software, a programmer must be familiar with common algorithmic approaches and the data structures they manipulate. And because programs must ultimately be executed by computers, the connection between algorithms and underlying hardware must also be understood.
One application area in which the design of new algorithms has had great impact is encryption. Encryption is the process of encoding a message so that it is decipherable only by its intended recipient. Since the time of Julius Caesar (100-44 B.C.), people have developed various algorithms for encrypting secret messages to ensure military, political, and even commercial security. For example, Caesar is known to have used an algorithm that involved replacing each letter in a message with the letter three positions later in the alphabet. Thus, the phrase "ET TU BRUTE" would be encrypted as "HW WX EUXWH", as 'H' is three positions after 'E', 'W' is three positions after 'T', and so on. Of course, for the message to be decrypted (i.e., to extract the original content), the recipient must understand the encryption method and perform the reverse translation.
The Caesar algorithm is known as a substitution cipher, since each letter in a message is substituted with a different letter (in this case, the letter three later in the alphabet). In general, any pattern of letter substitution can be applied. FIGURE 3 contains an interactive visualizer of the Caesar algorithm. The key specifies the code letters that are mapped to by the alphabet. Note that the 'A' in the alphabet box corresponds to 'D' in the key box, 'B' in the alphabet box corresponds to 'E', and so on. You can enter a message in the box on the left, then click the "Encode" button to see its encoding on the right. Similarly, you can enter an encoded message in the box on the right, then click the "Decode" button to decrypt it on the left.
| According to the substitution cipher, each letter: | |
| is encoded using the corresponding letter in the key: |
|
|
FIGURE 3. Substitution cipher visualization (Note: only capital letters are encoded).
✔ QUICK-CHECK 7.7: Enter a message, in all capital letters, in the box on the left. Then, click the "Encode" button to see the corresponding encoded message on the right. Next, delete the message on the left and click the "Decode" button. This should decode the message in the right box and display the original message on the left.
The visualizer in FIGURE 3 can be generalized to any substitution cipher, simply by changing the order of the letters in the key box. For example, changing the key box contents to QWERTYUIOPASDFGHJKLZXCVBNM would produce a completely different substitution cipher, where 'A' is mapped to 'Q', 'B' is mapped to 'W', and so on.
✔ QUICK-CHECK 7.8: Change the contents of the key box to QWERTYUIOPASDFGHJKLZXCVBNM and use the visualizer to encode and decode the same message you used in the QUICK-CHECK 7.6. Is the encoded message different than before? Does it still decode correctly?
A substitution cipher may be categorized as a private-key encryption algorithm because it relies on the sender and recipient sharing a private key that no one else has access to. Although substitution ciphers are not very secure by modern standards, we now possess more complex private-key algorithms, enabling parties to transmit sensitive information across networks without fear that their data will be compromised. For example, in 2002 the U.S. government adopted the Advanced Encryption Standard (AES) for encrypting sensitive data. The current version of AES uses a 256-bit number as the key. Decrypting an AES-encrypted message without knowing the key is virtually impossible, as this process would involve performing trial-and-error tests on 2256 ≅ 1077 possible keys. To appreciate just how large this number is (a 1 followed by 77 zeros), note that it is roughly the same as the number of atoms in the entire universe. The steps required to encrypt, send, and decrypt a message using private-key encryption are illustrated in FIGURE 4.
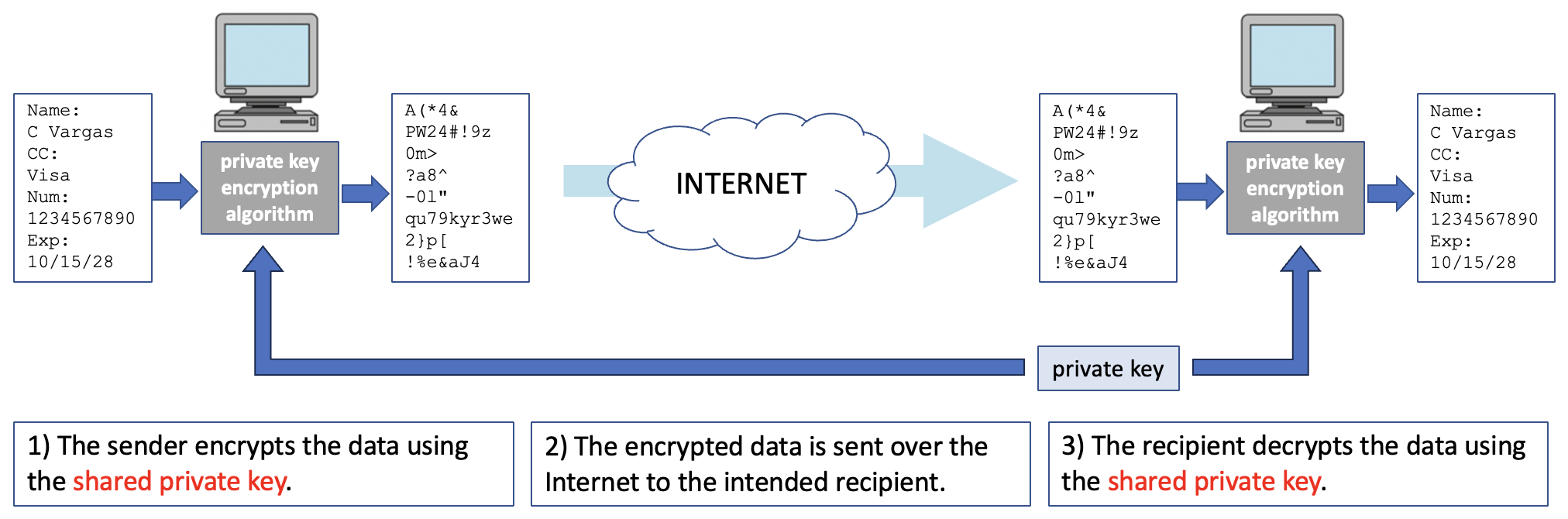
FIGURE 4. Private-key encryption across the Internet.
Private-key encryption algorithms rely on the assumption that the sender and recipient have agreed upon the secret key ahead of time. However, the exchange of keys for private-key encryption introduces additional security concerns because anyone who intercepts the key will be able to decrypt subsequent messages. In situations that require extreme security — for example, the transfer of sensitive government documents — the involved parties might go to great lengths to ensure a safe exchange of keys, such as by arranging a face-to-face meeting. Unfortunately, these sorts of measures are clearly not feasible for other types of communications, such as the exchange of messages or credit information over the Internet.
Secure online transactions use a different class of encryption algorithms, known as public-key encryption. Invented by Whitfield Diffie (1944-) and Martin Hellman (1946-) in 1976, public-key encryption uses two distinct (but related) keys for encrypting and decrypting messages. A public key is used to encrypt the message, which can then only be decrypted using the corresponding private key. The advantage of this approach is that a secure message can be sent to someone without having to exchange a secret key — only the recipient's public key is needed to encrypt the message (FIGURE 5).
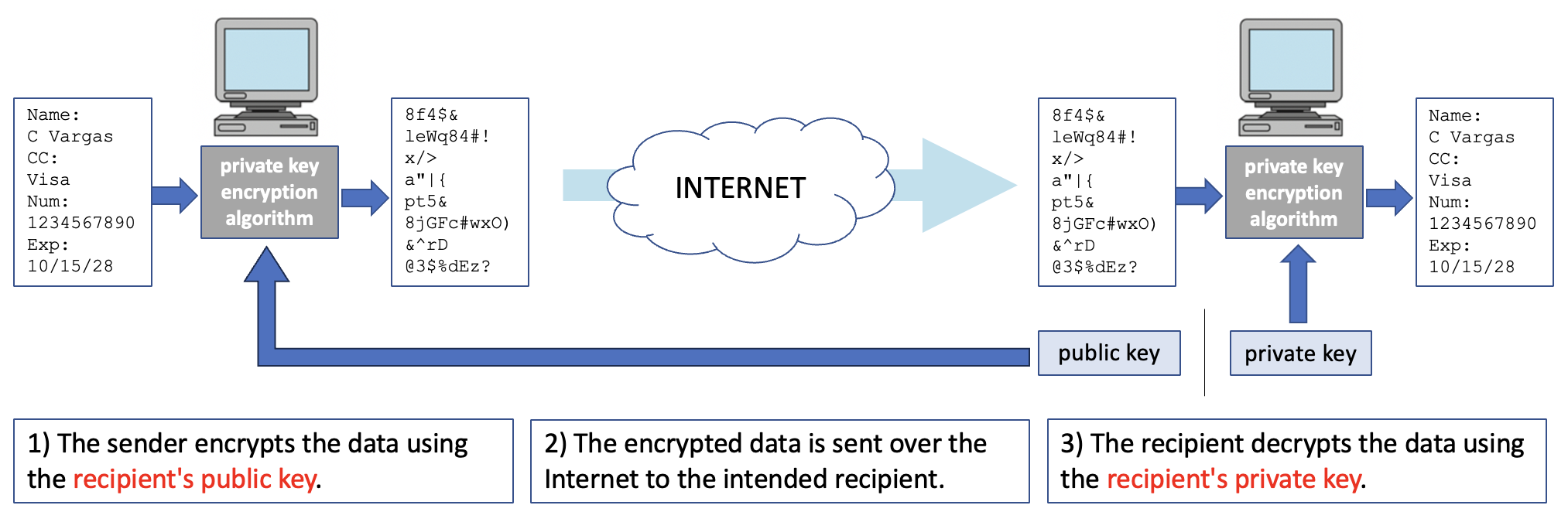
FIGURE 5. Public-key encryption across the Internet.
The RSA algorithm, invented in 1977 by Ron Rivest (1947-), Adi Shamir (1952-), and Len Adleman (1945-) at MIT, was the first practical implementation of a public-key encryption algorithm and provides the basis for almost all secure communications occurring over the Internet. For example, when a customer purchases an item from a Web-based retailer, such as Amazon.com, public-key encryption is automatically used to transmit credit card information in a safe and secure manner. In particular, the following steps are followed: (1) the customer's browser contacts Amazon's server to request a transaction; (2) the server responds by generating a public/private key pair, sending the public key back to the browser and storing the private key securely; (3) when the browser receives the public key, it encrypts the customer's data using that key and transmits the encrypted data to the server; (4) when the server receives that encrypted data, it decrypts it using the secure private key, completes the transaction, and then deletes the private key (FIGURE 6). Note that the use of public-key encryption ensures the security of the sensitive data while only requiring the sharing of the public key. Even if a thief intercepts the message, the encrypted data cannot be extracted without the corresponding private key, which is known only to the retailer.
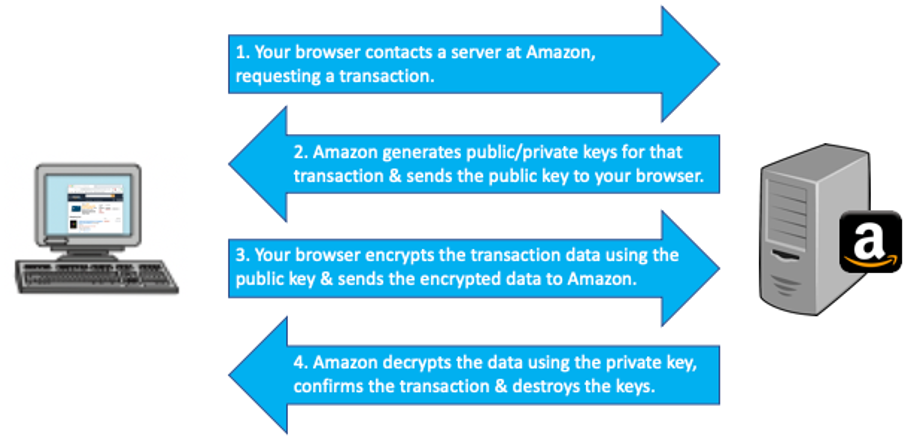
FIGURE 6. The use of public key encryption for e-commerce.
✔ QUICK-CHECK 7.9: TRUE or FALSE? Private-key encryption algorithms require the sender and recipient of a message to agree upon a secret key (or password) for encoding and decoding the message.
✔ QUICK-CHECK 7.10: Using public-key encryption, a message can safely be sent between two parties without having to exchange a secret key.
Architecture
The Architecture subdiscipline of computer science is concerned with methods of organizing hardware components into efficient, reliable systems. As we have discussed, the design of most computer systems is based on the von Neumann architecture. However, within this model, new technologies and techniques are constantly being developed to improve system performance and capabilities. For example, Chapter C4 outlined the historical evolution of computers, explaining how new technologies for switching electrical signals (e.g., relays, vacuum tubes, transistors, and finally integrated circuits) facilitated the introduction of smaller, cheaper, and more accessible computers. Other improvements in areas such as microchip manufacturing, memory storage and access, and input/output methods have also contributed to the construction of more powerful and usable systems (FIGURE 7).

FIGURE 7. Computer-controlled robots are used to manufacture microchips on a miniscule scale (Robert Kerton/Wikimedia Commons).
In recent years, computer architectures that deviate from the traditional von Neumann model have been developed and used effectively in certain application areas. Parallel processing, as its name suggests, is an approach that employs multiple processors working in parallel to share a computational load. Ideally, if you doubled the number of processors in a system, your program could conceivably accomplish its task in half the time, as the processors can handle subtasks simultaneously. In practice, however, additional computation is required to divide up the work, and not all tasks are well suited for parallel processing. For example, if each step in an algorithm is dependent on the results from the previous step, then the steps must be executed one at a time in the specified order, and additional processors will be of little help. Even when a task can be broken up, there are costs associated with coordinating the processors and enabling them to share information. Evaluating how and when parallel processing can be effectively applied to solve problems is a complex process. For example, an architect who works on parallel-computing systems must understand theory (in order to divide the algorithmic steps among the processors) and software methods (in order to specify control information within programs), as well as the design and implementation of hardware.
As we discussed in Chapter C1, multicore CPUs support simple parallel processing by packaging the circuitry for multiple processors on a single chip. For example, Intel's Core i3 (2010) contained two processor cores that could execute programs independently. The Core i5 and Core i7 (2010) each contained four cores, while the Core i9 (2018) contained eight or ten cores. With a multicore CPU, the operating system will attempt to distribute programs so that the processing load is shared equally by the processors. Even a casual computer user can experience the benefits of this type of parallel processing. Suppose you were listening to music on a computer while simultaneously surfing the Web or editing a document. With multiple cores, each program could be assigned to a separate core and so could execute independently. In contrast, with a single core CPU, you might experience degradations in music quality due to the programs sharing the same CPU.
Web servers are another common application of parallel-computing technology. Recall that a Web server manages Web pages and other resources, such as images and sound files. When a browser communicates a request to a server, the server must respond by first locating and then sending the appropriate resources back to that browser. Because a Web server may be called upon to service multiple independent requests during a short period of time, many Web servers distribute their computational loads among multiple processors. Thus, numerous page requests might be served simultaneously by different processors within the Web server.
More extreme implementations of parallel processing can be seen in a family of supercomputers from IBM. The Deep Blue chess-playing computer, developed in the mid 1990s, contained 32 general-purpose processors and 512 special-purpose chess processors, each of which could work in parallel to evaluate potential chess moves. Together, these processors could consider an average of 200 million possible chess moves per second! In 1997, Deep Blue became the first computer to beat a world champion in a chess tournament, defeating Garry Kasparov in six games. IBM applied the lessons learned from Deep Blue to eventually build the Watson computer, which employed a cluster of 90 servers containing 2,880 processors. In 2011, Watson beat Jeopardy champions Brad Rutter and Keith Jennings in a $1 million dollar challenge match (FIGURE 8) and is currently used in a variety of applications including weather prediction, medical diagnosis, and satellite imagery analysis.

FIGURE 8. IBM Watson on Jeopardy, 2011 (VincentLTE/Wikimedia Commons).
✔ QUICK-CHECK 7.11: Parallel processing employs multiple processors working in parallel to share a computational load.
Software Engineering
The Software Engineering subdiscipline is concerned with creating effective software systems. The development and support of computer software has become a major factor in the information-based economy of the 21st century. The U.S. software industry is projected to generate $380 million in revenue in 2025, and to exhibit a steady annual growth rate of 3.98% through 2030 (Statista, 2025).
Developing large, reliable, cost-effective software systems can be extremely difficult, as it presents both technical and management challenges. Large software projects can encompass millions of lines of code, requiring extensive teams of programmers and analysts. For example, modern operating systems are estimated to contain anywhere from 50 million to 90 million lines of code. When teams of programmers are working together on the same project, software must be carefully designed so that components can be developed and tested independently, then integrated into the whole. A variety of tools are used to facilitate this, including design formalisms (such as the Unified Modeling Language, or UML) that clearly define the intended behavior of software components, and version control systems (such as GitHub) that allow multiple programmers to share files and safely integrate changes.
In addition, the efforts of the individual developer must be coordinated to ensure that work is not being duplicated and that the individual components being developed will fit together as a whole. As the software components are developed, they must be tested in isolation and again as part of the overall project to ensure that they are correct and reliable. Testing and maintaining software after it is completed (as bugs or found or new features are added) is a major task, often exceeding the cost of development by a factor of 2-4. Effective software engineering requires an overall development methodology that addresses all aspects of the software life cycle (FIGURE 9).

FIGURE 9. The software life cycle.
Currently, the dominant approach to software development in industry is known as Agile development. Agile development focuses on fast but flexible development, with frequent team and customer collaboration. It starts by developing a crude but working prototype of the desired software. This prototype is then expanded in incremental phases, which include identifying a set of missing features to focus on, planning and implementing those features, testing the updated software, and reviewing the outcome. By developing the software in small increments, the developers can be flexible and change the design based on test results or customer input.
There are multiple schemes for organizing and carrying out the Agile development process. A popular framework is Scrum, which formalizes each phase into a structured, 2-4 week process called a "sprint." The diagram in FIGURE 10 shows the steps involved in each Scrum sprint.
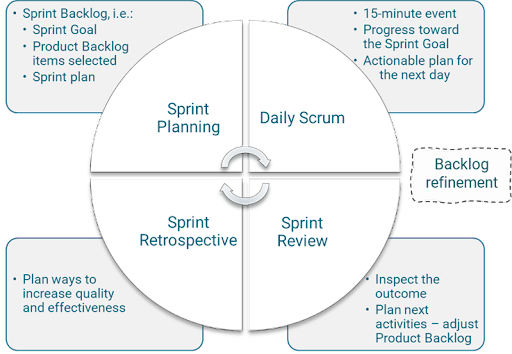
FIGURE 10. Agile development using the Scrum approach (Stefan Morcov/Wikimedia Commons).
An important trend in software development is the Open Source movement. Open Source is a collaborative, community-based approach to developing and testing software. Any qualified developer can contribute to an Open Source project, and the resulting software is freely available to all, including source code that users can download and adapt to fit their needs. While many of those working on Open Source projects are volunteers, companies frequently assign their own developers to contribute to projects, which can be more cost-effective than developing the project on their own.
✔ QUICK-CHECK 7.12: TRUE or FALSE? Designing and implementing software systems requires the bulk of development time.
✔ QUICK-CHECK 7.13: TRUE or FALSE? Agile development is a popular approach to software development, which focuses on incremental development and flexibility in design.
Artificial Intelligence
One of the best-known subdisciplines of computer science is Artificial Intelligence (AI), which aims to design computer systems that exhibit more humanlike characteristics — i.e., the ability to see, hear, speak, and even reason. In his 1950 paper, Computing Machinery and Intelligence, Alan Turing predicted that, by the end of the 20th century, the intelligence exhibited by programmed machines would rival that of humans. In fact, he proposed a process, now known as the Turing Test, for identifying artificial intelligence (FIGURE 11).

FIGURE 11. The Turing Test for Artificial Intelligence.
Although his prediction turned out to be optimistic and thinking machines are still years away (if even possible), much progress has been made in areas such as robotics, machine vision, and speech recognition. Robots are used extensively in manufacturing and some robotic products, such as self-guided vacuum cleaners, are common in private homes (FIGURE 12).

FIGURE 12. Manufacturing robots assembling an automobile (Steve Jurvetson/Wikimedia Commons); robot vacuum cleaner (Mamirobothk/Wikimedia Commons).
There are two major approaches to developing AI systems. If the knowledge and reasoning required is straightforward and focused in a narrow domain, an expert system can be developed. Expert systems are programs that encapsulate the knowledge and reasoning of experts in that domain, usually in the form of rules that can be applied to perform a task. Expert systems have been highly effective in specialized medical diagnosis, where medical experts' knowledge can be encoded in rule form. For example, the FocalPoint Primary Screening System from BD Diagnostics is an expert system that is commonly used by doctors to process Pap test slides and detect early signs of cervical cancer. Most customer service phone lines utilize an expert system to prompt the operator with questions and answers based on caller behavior. Tax preparation software, such as H&R Block and TurboTax, contain complex expert systems, which formalize the tax codes into rules. These expert systems enable the user to complete their tax forms by answering simple questions that adapt to their financial details.
When it is difficult to format knowledge into rules, or the domain is so complex that rule-based reasoning is impractical, different methods are required. Machine Learning is an approach to AI development that focuses on training the software to learn and improve its behavior. A good example of this approach is optical character recognition. When you scan a printed or hand-written document, the individual characters of that document must be identified to create the digital equivalent. Since there are many font options and variances in human script, it would be impractical to define the difference between a 1 and a 7 in rules. Instead, the software is fed hundreds or thousands of examples of each character, and it uses complex learning algorithms to identify the defining characteristics of each. Facial recognition software uses a similar approach, where thousands of images of faces are fed into the system, and it learns to identify defining characteristics, such as lip thickness and the distance between eyes. In a similar way, self-driving cars are trained to recognize the boundaries of a road and obstacles to avoid.
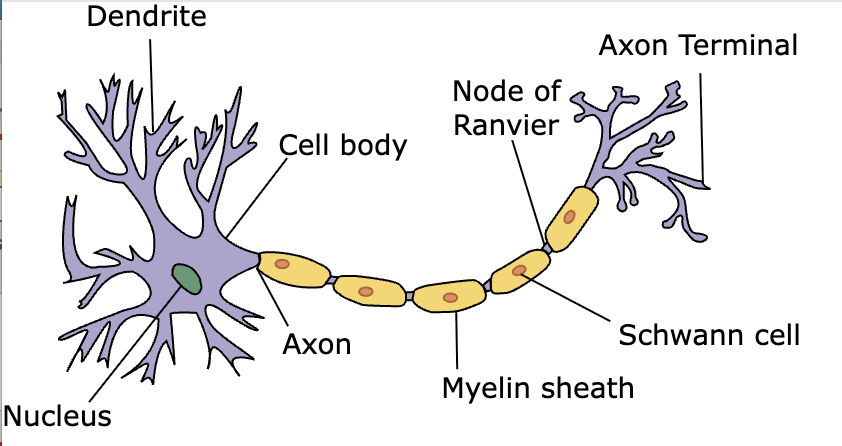
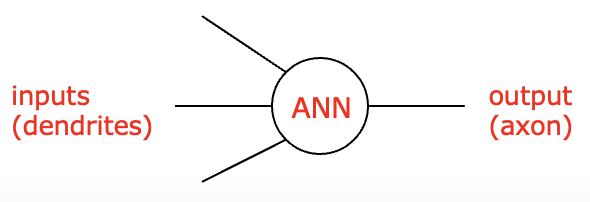
Underlying most machine learning applications is a neural network model that mimics the way the human brain is configured. The brain is a massive network of interconnected neurons, cells in which electrical impulses enter the cell through dendrites. Depending on the number and strengths of the impulses, the neuron may fire an impulse through its axon (FIGURE 13, left). Psychologists in the 1940s noted that the behavior of neurons could be captured by a simpler model, known as an artificial neuron (FIGURE 13, right). An artificial neuron can have multiple inputs (corresponding to dendrites), a single output (corresponding to an axon), and a function that maps the input to an output (corresponding to firing an impulse).
|
|
FIGURE 13. Diagram of a neuron (Dhp1080/Wikimedia Commons); An artificial neuron.
Artificial neurons can be interconnected to form a neural network, which models the interconnected neurons of the human brain. When humans are born, their brains have some behaviors (e.g., crying when hungry) prewired. Most human knowledge and capabilities, however, are learned through experience. When a toddler touches a hot kettle, they experience pain and learn not to do that again. Similarly, neural networks are trained on data selected by the software developers (often referred to as knowledge engineers) and learn to recognize patterns though experience. FIGURE 14 shows a simplified model of a neural network for character recognition. Artificial neurons are connected into a grid, with each corresponding to a pixel in the scanned image. The artificial neurons in the input grid are connected to a hidden layer of neurons that are trained to recognize features within the character image (e.g., a horizontal line near the top). Those neurons connect to the output layer, which predicts the character based on the identified features.
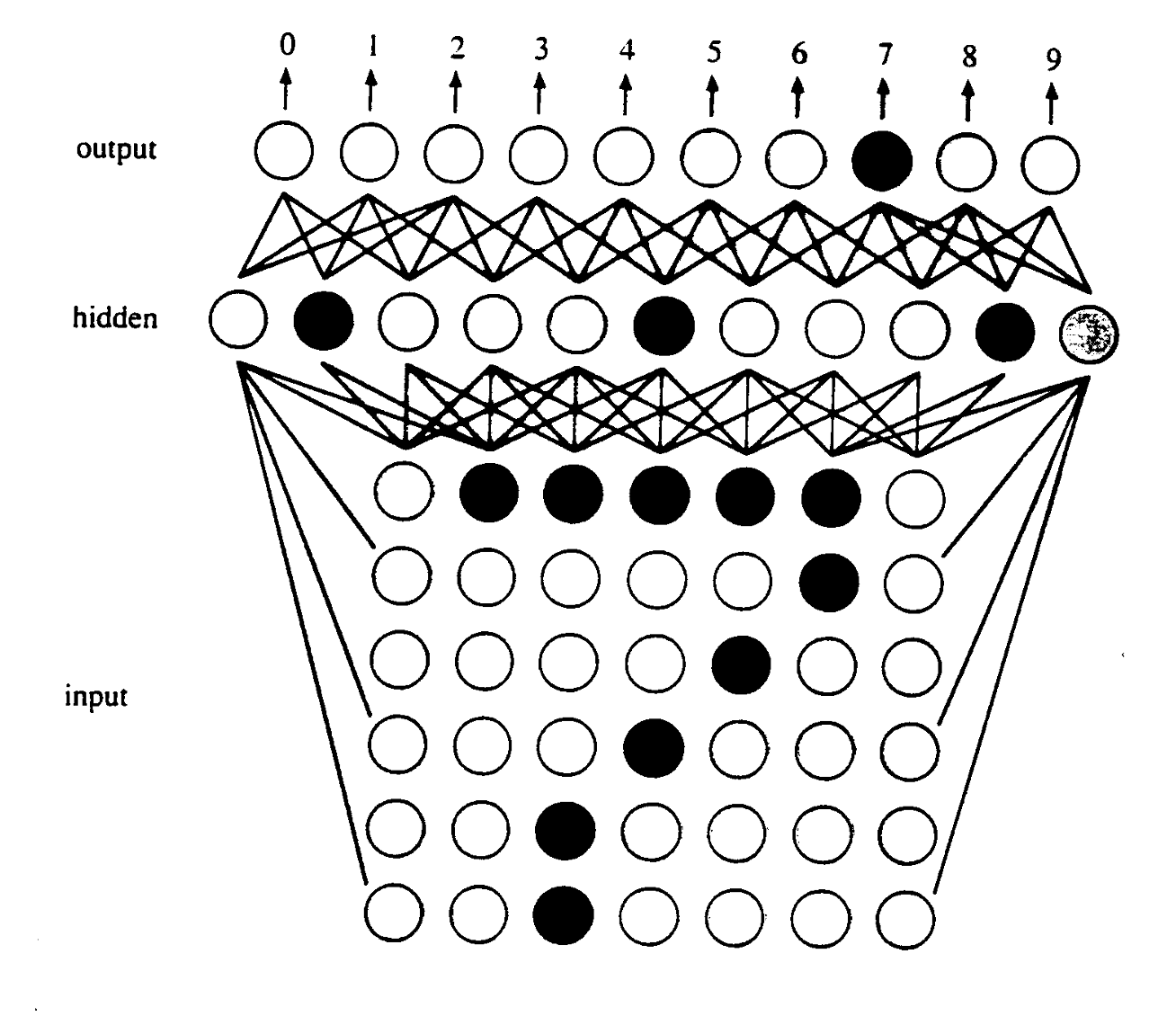
FIGURE 14. Simplified neural network to perform character recognition.
A subset of Machine Learning AI that is rapidly changing how people study and work is Generative AI. Generative AI tools, such as OpenAI ChatGPT, Microsoft Copilot, and Midjourney Inc. Midjourney, utilize neural networks to enable individuals to answer questions, write essays, develop software, and create multimedia. The underlying neural networks are trained on massive amounts of input, some obtained from human interaction, and some extracted for documents and Web pages. Because of the creative power these tools exhibit, experience using Generative AI tools is becoming a requirement for many jobs. In fact, the 2024 Work Trend Index from Microsoft and LinkedIn reported that 66% of business leaders claimed they would not hire a candidate without AI skills.
✔ QUICK-CHECK 7.14: The Turing Test was proposed by Alan Turing as a means of determining whether self-aware, artificial intelligent has been achieved.
✔ QUICK-CHECK 7.15: A neural network is a network of computers that is fault-tolerant due to redundant connections.
The Ethics of Computing
Despite the diverse approaches taken by the various computer science subdisciplines, computing professionals have much in common. All perform work relating to the three themes (theory, software, and hardware), and all contribute to computing's overall impact on society. Careers in this computing continue to be attractive and challenging, with computer professionals in high demand and salaries that are among the highest of any discipline.
In an effort to unite computing professionals into a cohesive community, professional organizations supervise the creation and dissemination of industrywide resources. This includes publishing journals relevant to the discipline, organizing conferences, providing career resources, and representing technology workers' interests to government and society. The oldest and largest professional organization is the Association for Computing Machinery (ACM), founded in 1947. However, the industry supports numerous similar groups, such as the IEEE Computer Society, which also originated in the late 1940s and is especially popular among computing professionals with engineering backgrounds.
In 1992, the ACM responded to society's increasing reliance on technology and technology workers by adopting a Code of Ethics and Professional Conduct for computing professionals. This code, which was updated and modernized in 2018, outlines computer professionals' responsibilities for ensuring that hardware and software are used safely, fairly, and effectively. Excerpts from this code are listed in FIGURE 15. The moral imperatives provided in section 1 of the code represent general guidelines relevant to any computing professional. For example, all ethical citizens are expected to behave fairly to all (imperative 1.4) and honor others' property and intellectual rights (imperatives 1.5 and 1.6). Section 2 of the code relates specifically to computing and the need to protect technology users from incompetence and unethical practices in the computing industry. For example, imperative 2.5 recognizes that computer technology plays a role in critical systems, such as those in which human life (e.g., medical monitoring systems) and property (e.g., banking systems) are at risk. This part of the code indicates that computer professionals must understand the potential impact of their work and strive to minimize risks. A related section, imperative 2.7, implies that computer professionals are obligated to publicize the societal impacts of computing, including the inherent risks associated with our technological dependence.

FIGURE 15. Excerpts from the ACM Code of Ethics.
✔ QUICK-CHECK 7.16: TRUE or FALSE? According to the ACM Code of Ethics, a computer professional is responsible for understanding the potential impact of their work and for striving to minimize risks to the public.
Chapter Summary
- Computer science is the study of computation, encompassing all facets of problem solving including the design and analysis algorithms, the formalization of algorithms as programs, and the development of computational devices for executing those programs.
- Computer science shares common elements with natural sciences, including a rigorous approach to understanding complex phenomena and solving problems. However, computer science has been classified by some as an "artificial science," because the systems studied by computer sciences are largely designed and constructed by people.
- The three recurring themes that define the discipline of computer science are hardware (the physical components of computers), software (the programs that execute on computers), and theory (an understanding of the capabilities and limitations of computers).
- A Turing machine is an abstract model of computation designed by Alan Turing in 1930. Using this model, Turing was able to demonstrate that there exist problems whose solutions cannot be computed.
- The discipline of computer science encompasses many subdisciplines, including Algorithms, Architecture, Software Engineering, and Artificial Intelligence.
- The Algorithms subdiscipline involves developing, analyzing, and implementing algorithms for solving problems. For example, the development of new algorithms for encrypting data and messages (e.g., public-key and private-key encryption) has had significant impact on electronic commerce and security.
- The Architecture subdiscipline is concerned with methods of organizing hardware components into efficient, reliable systems. For example, new architectures in which multiple processors work in parallel to share a computational load have produced powerful results (e.g., the Deep Blue computer that beat a world champion in chess).
- The Software engineering subdiscipline is concerned with creating effective software systems. Stages in the development and maintenance of software projects include requirement analysis and specification, design, implementation, testing, operation and maintenance.
- The Artificial Intelligence subdiscipline aims to design computer systems that exhibit more humanlike characteristics. Commercial successes in this area of research include expert systems and manufacturing robotics.
- Expert systems are AI applications that codify the knowledge of experts into rules that can be applied to perform a task.
- A neural network is the underlying model of Machine Learning, in which a network of artificial neurons is trained to recognize patterns or perform some task.
- In 1992, the Association for Computing Machinery adopted a Code of Ethics and Professional Conduct for computing professionals that identifies general moral imperatives and specific responsibilities of professionals in information technology. This code of ethics was revised and modernized in 2018.
Review Questions
- TRUE or FALSE? The three recurring themes that define the discipline of computer science are hardware, software, and theory.
- Describe at least two similarities between computer science and natural sciences such as physics, biology, and chemistry. Describe at least two differences.
- Alan Turing is considered one of the founders of computer science. Describe two of his contributions to the discipline and explain the importance of those contributions.
- Encrypt the message "Beware the Ides of March" using the Caesar encryption algorithm. Recall that the Caesar algorithm encodes each individual letter by replacing it with the letter three positions later in the alphabet (and wrapping if necessary).
- The following encoded text was created using Caesar's encryption algorithm: "Brx jrw lw". Decode this message by performing the reverse translation.
- Using public-key encryption, the sender and recipient of a message do not need to agree on a shared secret key before initiating secure communications. How is this possible? That is, how can the sender, using publicly available information, encode a message that can be decoded only by the intended recipient?
- Describe the fundamentals of parallel processing and explain how they are implemented in Deep Blue, the first computer to defeat a world chess champion in a tournament setting.
- Describe the individual steps that make up the software life cycle. What is the life cycle's significance in relation to the software engineering process?
- Imagine that you are serving as the judge in a Turing Test. Describe the strategy you would use to identify the computer. That is, what kinds of questions would you ask the contestants, and how would the answers you received help you differentiate between the computer and human?
- Software piracy, the unauthorized copying of software without payment to the legal owner, is a growing problem worldwide. Suppose that you were offered a chance to copy a friend's disk containing copyrighted software. What portions of the ACM Code of Ethics would address this situation? According to the code, how should a computer professional respond to such an offer?
- Imagine that you are working for a software company, writing a program that will control air traffic at major airports. Management is pressuring you to complete the program on schedule, but you know that remaining bugs in the software might cause the program to fail under certain circumstances. What portions of the ACM Code of Ethics would address this situation? According to the code, how should you react to the situation?