
C3: The Internet
It shouldn't be too much of a surprise that the Internet has evolved into a force strong enough to reflect the greatest hopes and fears of those who use it. After all, it was designed to withstand nuclear war, not just the puny huffs and puffs of politicians and religious fanatics. — Denise Caruso
The Internet is the first thing that humanity has built that humanity doesn't understand. It's the largest experiment in anarchy that we've ever had. — Eric Schmidt
The Internet is a vast network of computers that connects people all over the world. Using the Internet, a person in Indiana can communicate freely with a person in India, scientists at different universities can share computing power, and researchers can access libraries of information from the comfort of their own homes or offices. It has been estimated that more than 5.52 billion people access the Internet regularly, or 67.5% of the world population. In the U.S. alone, more than 322 million people are regular Internet users, or 97% of the population [Statista, 2024].
This chapter will explore the history of the Internet, including its evolution from a network of computers to a network of "things." The main design features of the Internet, its distributed nature and packet switching, will be explained. Finally, the role of the TCP/IP protocols, which enable computers from across the world to effectively communicate, will be discussed.
History of the Internet
One of the most significant advancements in computing history is the Internet, the idea for which can be traced back to the early 1960s. While a professor at the Massachusetts Institute of Technology, J.C.R. Licklider (1915-1990) published a series of articles describing a "Galactic Network" of computers that would allow people worldwide to share and access information. Licklider was excited by the computer's potential to influence scientific and engineering research but was frustrated by the difficulties involved in accessing computers. Very few computers existed in the early 1960s, and those that were in use tended to be monopolized by a small number of researchers at major universities. Licklider believed that if computers could be connected over long distances so that a researcher in one state could access a computer in another, then a larger group of researchers would be able to benefit from the computer's capabilities. Such a network would also allow institutions to reduce computing costs by sharing resources.
In 1962, Licklider was appointed head of the computer research program at the U.S. Department of Defense's Advanced Research Project Agency (ARPA). As part of his job, he was asked to investigate how researchers — especially those working on defense-related projects — could better utilize computers. He immediately saw the opportunity to build his Galactic Network and began establishing relationships with the top computer research organizations in the country. Over the next few years, ARPA funded numerous network-related research initiatives, which generated the ideas and technology that would eventually lead to the Internet.
✔ QUICK-CHECK 3.1: TRUE or FALSE? Research and development on what would eventually become the Internet was funded primarily by the U.S. Department of Defense.
ARPANET
One of those inspired by Licklider's vision of a long-distance network was Larry Roberts (1937-2018), a computer researcher at MIT. In 1967, Roberts was named head of the ARPA project to design a long-distance computer network. Within a year, Roberts and his team had finalized plans for the network, which was to be called the ARPANET. In 1969, the ARPANET became a reality, linking four computers at the University of California at Los Angeles (UCLA), the University of California at Santa Barbara (UCSB), the Stanford Research Institute (SRI), and the University of Utah. The network employed dedicated cables, lines buried in the ground and used solely for communications between the computers. Researchers at the four institutions were able to connect to one another's computers and run programs remotely, meaning that researchers at multiple sites could share both hardware and software costs. In addition, researchers could share information by transferring text and data files from one location to another. It is interesting to note that the transfer rate between the computers—i.e., the speed at which data could be sent and received over the dedicated cables — was 56 Kbits/sec. This is roughly the same rate that Internet users in the 1980s and 1990s could achieve with a modem and standard phone lines. However, at the time, the ARPANET's communication speed represented a dramatic increase over the 160 bits/sec transfer rate obtainable over standard phone lines.
The U.S. Department of Defense originally intended the ARPANET to connect only military installations and universities participating in government projects. Throughout the 1970s, the ARPANET grew at a steady pace, as computers owned by various military contractors and research institutions were added to the network. FIGURE 1 shows a map of the ARPANET in 1970, where the number of connected computers had grown from the original four to eighteen.
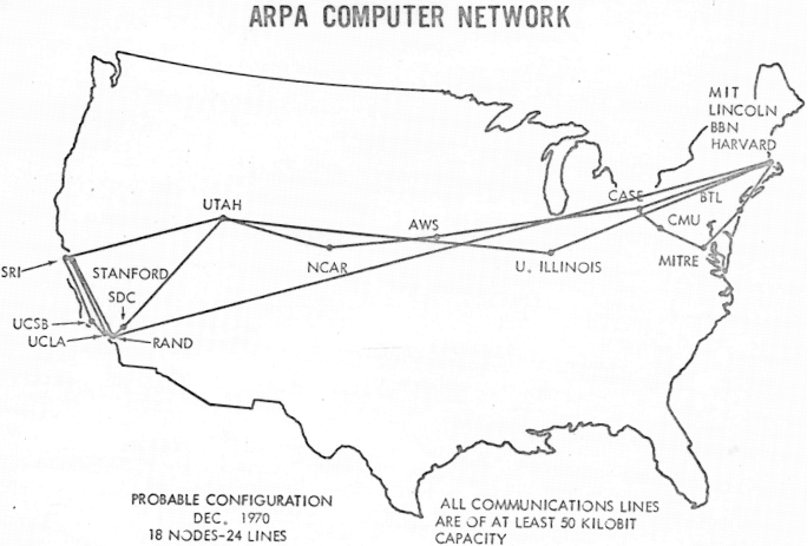
FIGURE 1. The ARPANET in 1970 (UCLA and BBN).
In the 1970s and 1980s, however, the ARPANET experienced an astounding growth spurt as more and more users were attracted by network applications such as electronic mail (through which users could send messages and files over the network), newsgroups (through which users could share ideas and results), and remote logins (through which users could share computing power). By 1984, the ARPANET encompassed more than 1,000 computers, far exceeding the expectations of its original designers (FIGURE 2).
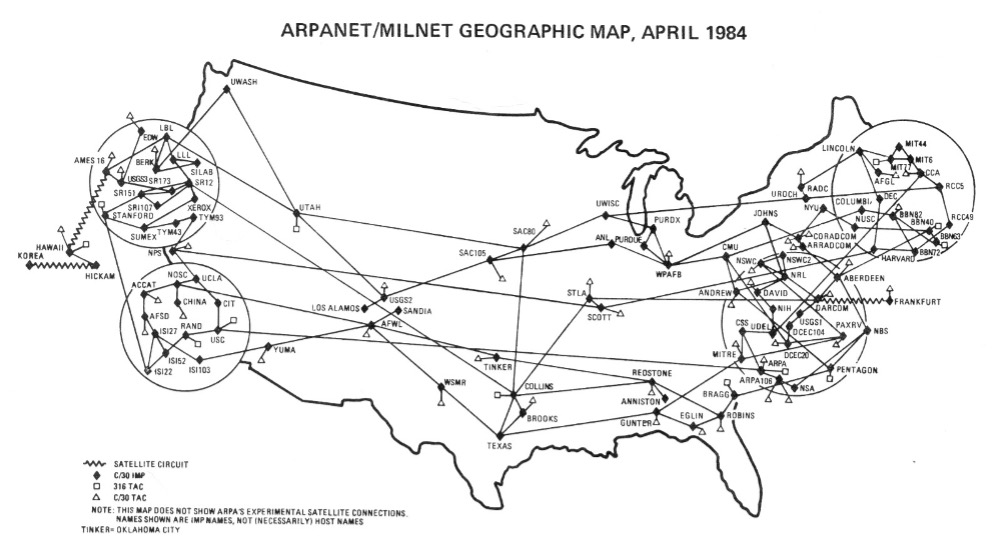
FIGURE 2. The ARPANET/MILNET in 1984 (UCLA and BBN).
✔ QUICK-CHECK 3.2: How many computers were connected to the ARPANET when it first went live in 1969?
ARPANET
To accommodate further growth, the National Science Foundation (NSF) became involved with the ARPANET in 1984. The NSF, an independent agency of the U.S. government that promotes the progress of science, funded the construction of high-speed transmission lines that would form the backbone of the expanding network. The NSFNET would eventually become known as the Internet in recognition of the similarities between this computer network and the interstate highway system. The backbone connections were analogous to interstate highways, providing fast communications between principal destinations (FIGURE 3). Connected to the backbone were transmission lines that provided slower, more limited capabilities and linked secondary destinations; these transmission lines could be compared to state highways. Additional connections were required to reach individual computers, in the same way that city and neighborhood roads are used to link individual houses.
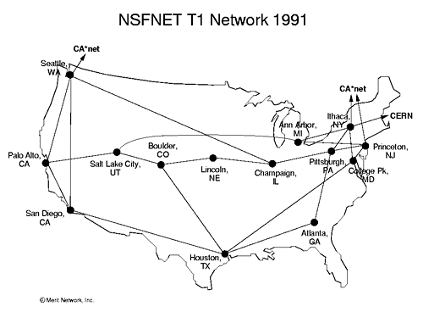
FIGURE 3. The NSFNET backbone in 1991 (Merit Network, Inc.).
Recognizing that continued growth would require an influx of funding and research, the government decided in the mid-1990s to privatize the Internet. Control of the network's hardware was turned over to telecommunications companies and research organizations, which were expected to implement new Internet technologies as they were developed. Today, most of the physical components that make up the Internet, including the high-speed backbone connections, are owned and maintained by commercial firms such as AT&T, Verizon, T-Mobile, and CenturyLink. Other aspects of the Internet are administered by the Internet Society, an international not-for-profit organization founded in 1992. The Internet Society maintains and enforces standards, ensuring that all computers on the Internet can communicate with each other. It also organizes committees that propose new Internet-related technologies and software and provides a managerial structure for determining when and how technologies are adopted. Key organizations within the Internet Society are identified in FIGURE 4.
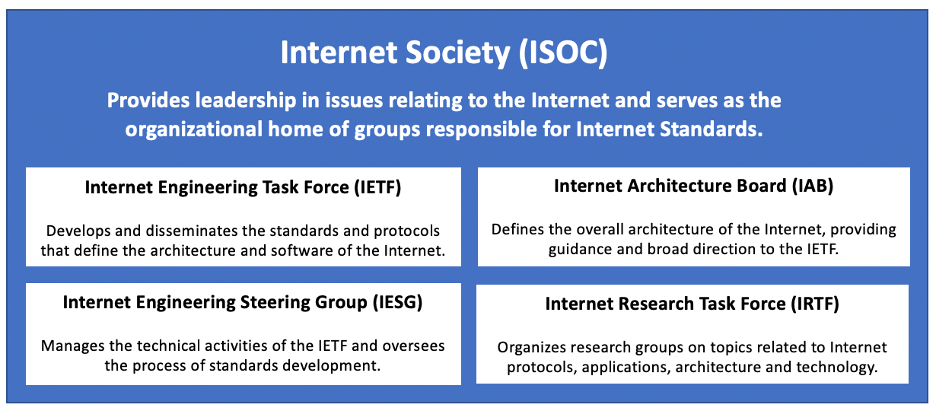
FIGURE 4. The Internet Society and its key organizations.
FIGURE 5 documents Internet growth over three decades, as estimated by the Internet Software Consortium (another not-for-profit organization involved in developing and promoting Internet standards). During the 1980s and 1990s, the Internet grew exponentially, with the number of computers connected to the Internet more than doubling every 1-2 years. That rate slowed in the 2000s, not so much because of declining interest but due to changes in how people accessed the Internet. In particular, the statistics from the Internet Software Consortium only count traditional computers. The 2000s marked the rapid growth of alternative technologies for accessing the Internet: smartphones, tablets, and other mobile devices. The popularity of these alternative devices meant that while growth in the number of computers accessing the Internet declined, overall connectivity has continued to expand at a remarkable rate.
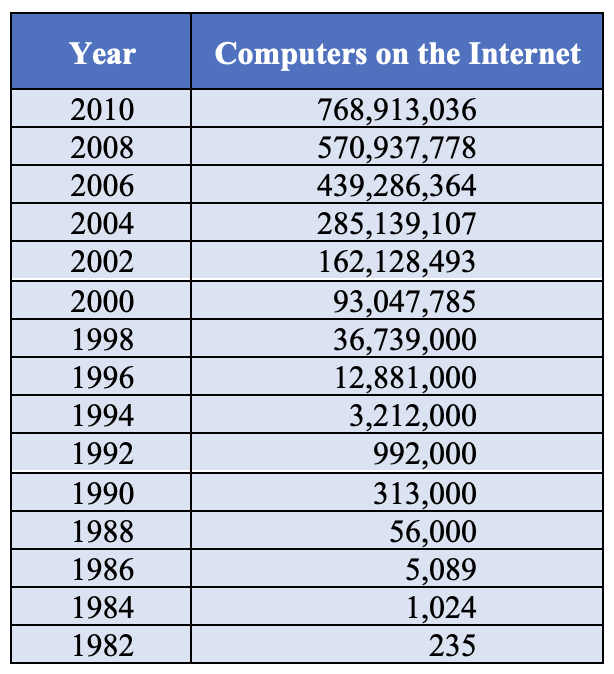
FIGURE 5. Internet growth (Internet Software Consortium).
✔ QUICK-CHECK 3.3: TRUE or FALSE? The Internet Society, an international not-for-profit organization, maintains and enforces standards for the hardware and software of the Internet.
The Internet of Things (IoT)
The diversification of the Internet, through the widespread adoption of smartphones and other mobile and embedded devices, has led people to think of the Internet in new ways. The term Internet of Things was first used in 1999 by computer scientist and entrepreneur Kevin Ashton (1968-). However, the term was not widely adopted until a 2011 white paper by Dave Evans at Cisco Systems, Inc. In this paper, Evans described the Internet of Things as a new stage in the evolution of the Internet, in which traditional computers were outnumbered by mobile and embedded devices. For example, a modern automobile may contain hundreds of processors, controlling engine function, antilock brakes, heads-up displays, satellite navigation, sound system, and more. These processors are networked together, and that localized network connects to servers from the automobile manufacturer and other service providers to diagnose problems, monitor performance, and provide access to maps, music, and other data. Similarly, smart devices are becoming common in homes, such as lights, thermostats, video cameras, and door locks that can be controlled via an Internet connection. As more and more aspects of modern life take advantage of the information and data services available via the Internet, the number of connected embedded devices continues to grow.
In the Cisco white paper, Evans cited 2009 as the official birth of the Internet of Things. It was during that time that number of devices connected to the Internet was estimated to exceed the world population (around 6.8 billion people, at that time). FIGURE 6 shows that the number of devices connected to the Internet exploded after that point, with 8.7 billion devices in 2010, 14.4 billion devices in 2012, 22.9 billion devices in 2016, and 34.8 billion devices in 2018. Cisco estimated that there were more than 50 billion devices connected to the Internet by the end of 2020, meaning more than six Internet connected devices per person on earth!
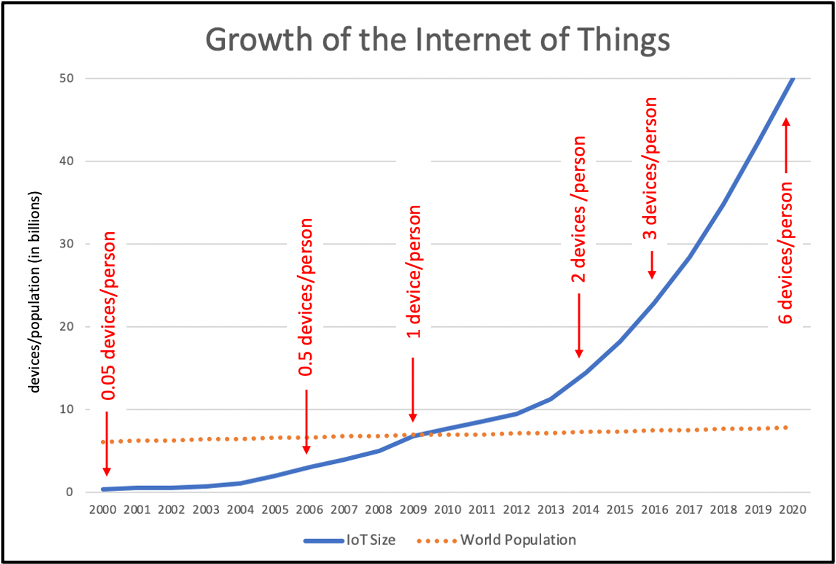
FIGURE 6. Growth of the Internet of Things. (Data from Cisco Systems, Inc.)
✔ QUICK-CHECK 3.4: The term Internet of Things refers to the fact that the Internet now connects all kinds of devices, from traditional computers to smartphones to smart devices in homes (e.g., lights or thermostats).
How the Internet Works
As we have mentioned, the ARPANET was novel in that it provided the first efficient computer-to-computer connections over long distances. However, the network's inherent organization was also innovative, representing a significant departure from telephone systems and other networking schemes of that era. The design of the ARPANET — and hence of today's Internet — was strongly influenced by the ideas of Paul Baran (1926-2011), a researcher at the Rand Corporation in the 1960s.
Distributed Network
The first of Baran's ideas adopted for the ARPANET was that of a distributed network. To fully understand the logic behind the Internet's structure, you must recall that funding for the ARPANET was provided by the U.S. Department of Defense, which had very specific objectives in mind. Given that the country was in the midst of the Cold War, the military wanted to develop a national communications network that would be resistant to attack. This goal required a design that allowed communication to take place even if parts of the network were damaged or destroyed, either by an enemy action or by normal mechanical failures. Clearly, a centralized network that relied on a small number of master computers to coordinate transmissions would not suffice. For example, the U.S. telephone network of the time relied on central hubs or switches that were responsible for routing service to entire regions. If a hub failed for some reason, entire cities or regions could lose service. Baran proposed a different architecture for a computer network, one in which control was distributed across a large number of machines. His design employed a lattice structure, in which each computer on the network was linked to several others. If a particular computer or connection failed, then communications could be routed around that portion of the network, and the network would continue to transmit data (FIGURE 7).
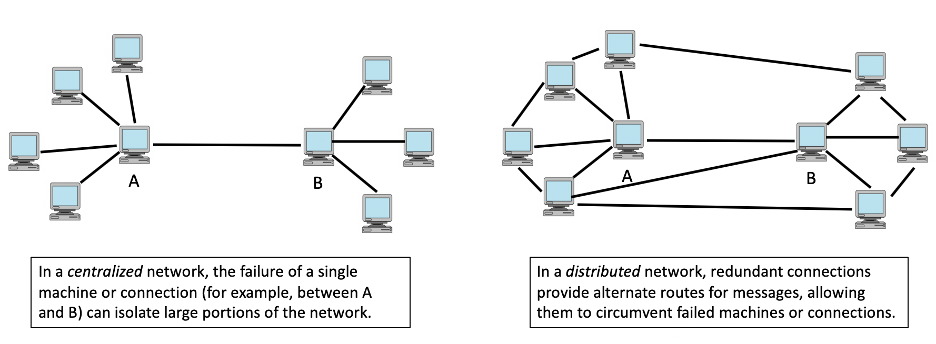
FIGURE 7. Centralized vs. distributed networks.
✔ QUICK-CHECK 3.5: TRUE or FALSE? In a centralized computer network, the failure of a single machine or connection can isolate large portions of the network.
Packet Switching
Baran's other idea central to the ARPANET architecture was that of packet switching. In a packet-switching network, messages to be sent over the network are first broken into small pieces known as packets, and these packets are sent independently to their final destination (FIGURE 8). Packet switching requires work at both ends of the transmission: software on the sender's computer must break the message into packets and label each packet for delivery; software on the recipient's computer must receive the individual packets and reassemble them to reconstruct the original message.
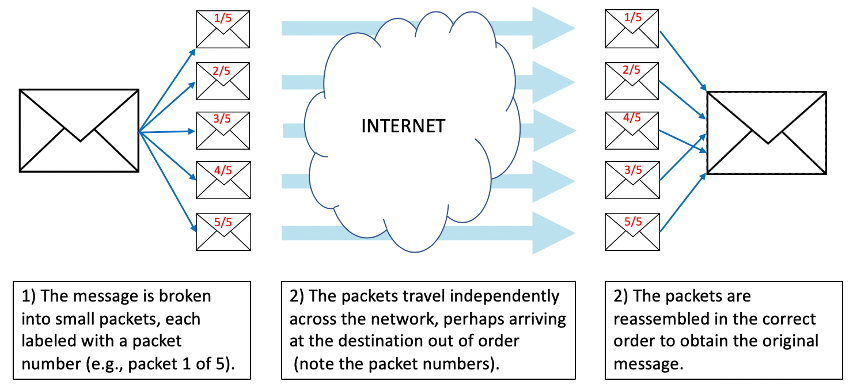
FIGURE 8. A packet-switching network.
Despite this overhead involved, packet-switching offers three key advantages:
- Sending information in smaller units increases the efficient use of connections. If a large message were able to monopolize a connection, many smaller messages might be forced to wait. As a real-life example of this effect, think of a checkout line at a busy grocery store. If the customer at the front of the line has a full cart of groceries, then everyone else in line must wait, even those who only need to purchase a few items. To avoid this, most grocery stores provide an express line where the number of items is limited. If purchases are limited to 10 items, for example, then each customer in the express line is guaranteed a turn in a reasonable amount of time. Similarly, limiting the size of network transmissions allows many users to share the connections in a more equitable manner.
- Packet switching allows the network to react to failures or congestion. As each packet works its way toward its destination, routers (special purpose computers on the network that control traffic) can recognize failures or network congestion and reroute the packet around trouble areas. As a real-life example, consider driving a car to a familiar destination. You most likely have a standard route that you take, but you might vary that route if you see heavy traffic ahead or know of road closings because of construction. In a similar manner, routers can adjust for congestion or machine failures as they direct each individual packet.
- The third advantage is that packet switching improves reliability. Even if there are failures within the network that cause packets to be lost, it is likely that at least some of the packets will arrive at the destination. From the packets that do arrive, software on the recipient's computer can identify which packets are missing and request retransmission from the sender.
✔ QUICK-CHECK 3.6: TRUE or FALSE? A router is a special-purpose computer on the Internet that receives message packets, accesses routing information, and passes the packets on toward their destination.
✔ QUICK-CHECK 3.7: TRUE or FALSE? When a message is broken into packets for transmission over the Internet, it is guaranteed that all packets will take the same route from source to destination.
Internet Protocols
Although the terms distributed and packet-switching can be used to describe the Internet's architecture, these characteristics do not address how computers connected to the Internet are able to communicate with one another. After all, just as people speak different languages and have different customs, computers are built using different technologies, operating systems, and computer languages. If the average American can't speak or understand Russian (and vice versa), how can we expect a computer in Minneapolis to exchange data with a computer in Moscow? To solve this problem, the computing community agreed on protocols, rules that describe how communication takes place. Internet protocols are analogous to the postal service address system, which is used to route letters and packages. If every state or country maintained its own method of labeling mail, sending a letter would be an onerous, if not impossible, task. Fortunately, protocols have been established for uniquely specifying addresses, including zip codes and country codes that allow letters to be sent easily across state and national borders. Similar protocols were established for the Internet to define how computers identify each other, as well as the form in which messages must be labeled for delivery.
Just as houses are assigned addresses that distinguish them from their neighbors, computers on the Internet are assigned unique identifiers known as IP addresses. An IP address is a number, usually written as a dotted sequence such as 147.134.2.84. Clearly, there are only a finite number of IP addresses, and their distribution must be coordinated to ensure that they are uniquely assigned. This task is managed by the Internet Corporation for Assigned Names and Numbers (ICANN), a not-for-profit coalition of businesses, academic institutions, and individuals that works with regional Internet registries to assign and keep track of IP addresses. Large or mid-size organizations might purchase a block of IP addresses from one of the regional registries and assign those addresses to its computers. For example, a university might purchase a few hundred IP addresses and assign them to computers in labs and offices. Individuals wishing to connect to the Internet usually do so through an Internet Service Provider (ISP), often the local cable or phone company. An ISP acts as an intermediary — purchasing a block of IP addresses from a regional registry and selling them to customers.
To save costs, many ISPs utilize dynamic IP addressing, which means that a customer's computer is not a assigned a fixed IP address but instead may be assigned a different address each time they connect to the network. This means that the ISP need not purchase an IP address for every customer, only enough to serve the maximum number of customers that connect simultaneously. For example, a cable company with 100,000 customers might determine that at most 20,000 customers will be connected to the Internet at the same time. To save costs, the company purchases 20,000 IP addresses and dynamically assign them to customers when they connect to the network. The ISP provider must then keep track of the current assignments, but the cost savings from the reduced number of IP addresses make this extra work worthwhile.
 Technically Speaking
Technically Speaking
The first major release of the Internet Protocol was IP version 4, or IPv4 (versions 1 through 3 were experimental versions). IPv4 introduced the IP address format that is still widely used today, with each address defined by a 32-bit number. To make the number easier to remember, a dot-decimal notation is commonly used, where the 32 bits are grouped into 4 bytes which are written in decimal, separated by dots. For example:
10010011100001100000001001010100 → 147.134.2.84
Since there are only 232 = 4,294,967,296 different 32-bit numbers, this means that there can be at most 4,294,967,296 different IP addresses. In the late 1970s when IPv4 was designed, approximately 100 computers were connected to the ARPANET, so it is understandable that designers did not see the limit of 4 billion addresses as a problem. With the evolution of the Internet of Things, however, it turned out that 4 billion addresses were simply not enough.
In 2017, the Internet Engineering Task Force adopted Internet Protocol version 6 (IPv6) as the new standard. IPv6 uses a 128-bit number for addresses, resulting in 2128 or more than 340 billion billion billion billion addresses! IPv6 addresses commonly utilize a dot-hexadecimal notation, where groups of 16 bits are represented by hexadecimal numbers, separated by dots. For example:
2600:8804:1a04:e700:d182:b8b9:b655:fda6
For the near future, IPv4 and IPv6 will coexist, with older networks utilizing the older, established protocol and newer networks upgrading to the new standard.
✔ QUICK-CHECK 3.8: TRUE or FALSE? Using a dynamic IP addressing scheme, the IP address assigned to a particular computer might change each time it connects to the Internet.
TCP/IP
Once a computer obtains its IP address and is physically linked to the network, the computer can send and receive messages, as well as access other Internet services. The manner in which messages are sent and received over the Internet is defined by a pair of protocols called the Transmission Control Protocol (TCP) and Internet Protocol (IP), which were co-developed in the early 1970s by Vinton Cerf (1943-) and Robert Kahn (1938-). TCP controls the method by which messages are broken down into packets and then reassembled when they reach their final destination. IP is concerned with labeling the packets for delivery and controlling the packets' paths from sender to recipient. The combination of these two protocols, written as TCP/IP, is often referred to as the language of the Internet. Any computer that can "speak" the language defined by TCP/IP will be able to communicate with any other computer on the Internet.
The overall process by which messages are broken into packets, labeled, sent over the Internet, and finally reassembled is described below (and illustrated in FIGURE 9).
- When a person sends a message over the Internet, specialized software using the rules of TCP breaks that message into packets (no bigger than 1,500 characters each) and labels the packets according to their sequence (e.g., packet 2 of 5).
- Next, software following the rules of IP labels those packets with routing information, including the IP addresses of the source and destination computers and the time the message was sent.
- Once labeled, the packets are sent independently over the Internet. Special-purpose machines called routers receive the packets, access the routing (IP) information, and pass the packets on toward their destination. The routers, which are maintained by the companies and organizations that manage the network connections, use various information sources, including statistics on traffic patterns, to determine the best path for each packet to follow.
- When the packets arrive at their destination, they may be out of order, owing to the various routes by which they traveled. TCP software running on the recipient's computer then reassembles the packets in the correct sequence to recreate the original message.
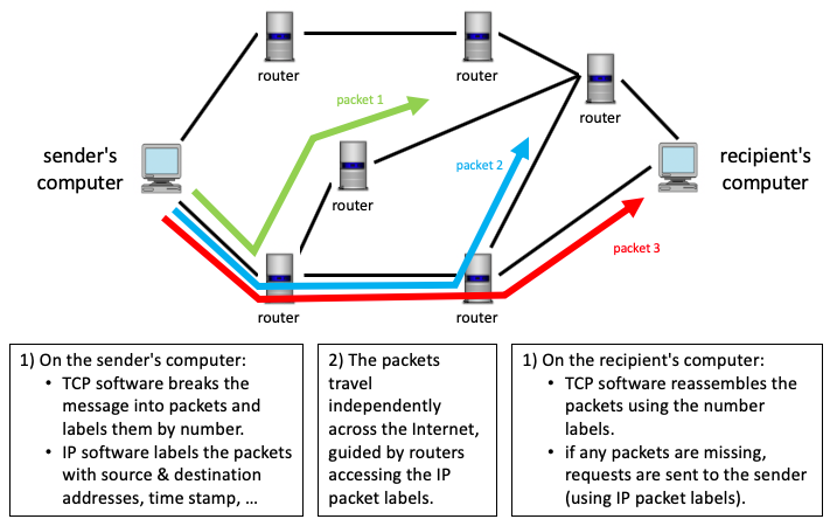
FIGURE 9. Transmitting a message over the Internet.
The infrastructure of the Internet supports hundreds of thousands of routers, those devices that receive and forward packets. Returning to the metaphor of the Internet as an information superhighway system, you can envision a router being located at each intersection or access ramp. When a router receives a packet, it must determine which connecting road to send that packet along. The labeling added by the Internet Protocol (IP) guides this routing. For example, the router might recognize the geographic location of an address and send the packet in the appropriate direction. To improve efficiency, routers constantly communicate with each other, notifying their neighbors as to how busy they are or if a connection on the network is known to be down. In that way, routers can avoid failed or busy connections and forward packets along routes that appear the fastest. As a result, different packets from the same message might take widely varying paths to the destination, as the traffic patterns between the routers shift in real time.
Despite the effort of routers to determine the safest and fastest route for a packet to take, failures still happen. For example, a connection or router might fail while a packet is in transit. This is where packet-switching helps — as long as some of the packets reach their destination, the recipient can identify the missing packet(s) from the TCP labels. The IP labeling includes timestamps on each packet, so after a reasonable amount of time has passed, any missing packets can be identified, and a message sent to the sender (who is identified in the IP labels) to resend those packets.
✔ QUICK-CHECK 3.9: TRUE or FALSE? As long as one packet from a message is received by the recipient's computer, TCP software can identify the missing packets and request they be resent by the sender.
Domain Names
From an Internet user's perspective, remembering the digits that make up IP addresses would be tedious and error prone. If you mistype only one digit in an IP address, you might mistakenly specify a computer halfway around the world. Fortunately, the Internet supports a domain-name system (DNS) where each individual machine is assigned a name that can be used in place of its IP address. For example, the computer with IP address 147.134.2.84 can be referred to by the name www.creighton.edu. Such names, commonly referred to as domain names, are hierarchical in nature, which makes them easier to remember. The leftmost part of a domain name specifies the name of the server, whereas the subsequent parts indicate the organization (and possibly suborganizations) to which the server belongs. The rightmost part of the domain name is known as the top-level domain and identifies the type of organization with which the server is associated. For example, the domain name www.creighton.edu refers to a server named www (a common name for Web servers) that belongs to Creighton University, which is an educational institution. Similarly, www.sales.acme.com refers to a server named www belonging to the sales department of a fictitious Acme Corporation, which is a commercial business. Since 1998, the assignment of domain names and IP addresses has been coordinated by the Internet Corporation for Assigned Names and Numbers (ICANN), which accredits companies known as domain-name registrars to sell and register domain-names.
FIGURE 10 lists examples of common top-level domains. However, you should be aware that these top-level domains are used primarily by American companies and organizations. Computers located in other countries are often identified by country-specific top-level domains, such as ca (Canada), uk (United Kingdom), cn (China), and in (India).
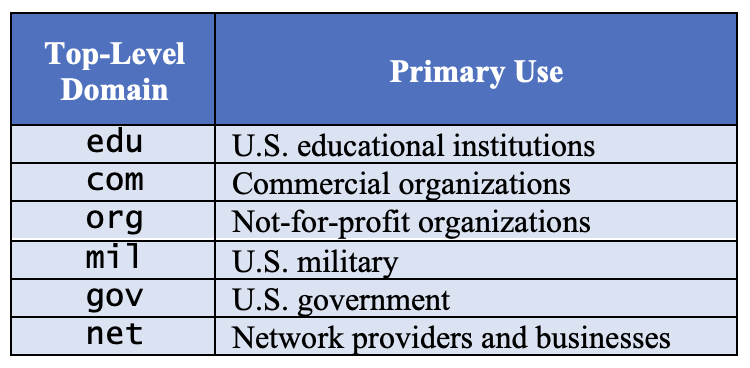
FIGURE 10. Top-level domain names.
Domain names help Internet users identify specific computers efficiently, because these names are much easier to remember than numeric IP addresses are. However, any communication that takes place over the Internet requires the numeric IP addresses of the source and destination computers. Special-purpose computers called domain-name servers are used to store mappings between domain names and their corresponding IP addresses. When a computer sends a message to a destination such as www.creighton.edu, the sending computer first transmits a request to a domain-name server, which matches the recipient's domain name to an IP address. After looking up the domain name in a table, the domain-name server returns the associated IP address (here, 147.134.2.84) to the sender's computer. This enables the sender to transmit the message to the correct destination. If a particular domain-name server does not have the requested domain name stored locally, it forwards the request to another domain-name server on the Internet; this process continues until the corresponding IP address is found (see FIGURE 11).
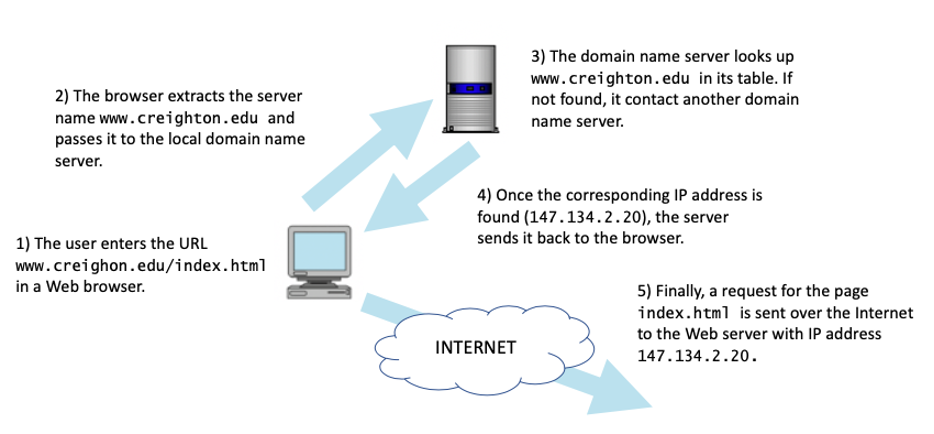
FIGURE 11. Domain-name servers translate domain names into IP addresses.
✔ QUICK-CHECK 3.10: TRUE or FALSE? A domain name server is a computer that receives message packets, accesses routing information, and passes the packets on toward their destination.
Chapter Summary
- The Internet traces its roots back to the ARPANET, which was funded by the U.S. Department of Defense's Advanced Research Project Agency (ARPA). In 1969, the ARPANET linked four computers at UCLA, UCSB, SRI, and Utah.
- The growth of the ARPANET in the 1970s greatly exceeded expectations, prompting the National Science Foundation (NSF) to become involved in the upgrading and maintenance of the ARPANET in 1984.
- In the mid-1980s, the ARPANET/NSFNET became known as the Internet, acknowledging its structural similarities with the nation's interstate highway system.
- Recognizing that continued growth would require an influx of funding and research, the government decided in the mid-1990s to privatize the Internet.
- In the past decade, the Internet has evolved into the Internet of Things (IoT), in which mobile and embedded devices have come to outnumber traditional computers.
- Researchers at Cisco Systems, Inc. estimated that there were more than 50 billion devices connected to the Internet by the end of 2020, meaning more than 6 devices per person in the world.
- The design of the ARPANET — and hence of today's Internet — was strongly influenced by the ideas of Paul Baran, who proposed that it be a distributed and packet-switching network.
- In a distributed network, control is distributed across a large number of machines, allowing for messages to be rerouted along alternate connections when a particular computer or connection fails.
- In a packet-switching network, messages are broken into smaller packets and sent independently. Advantages of this approach include a more efficient use of the connections, the ability to react to failures and congestion, and improved reliability.
- The Internet Society maintains and enforces standards and protocols concerning the Internet and organizes committees that propose new Internet-related technologies and software.
- Each computer on the Internet is assigned an IP address (e.g.,
147.134.2.84) that uniquely identifies it. IP addresses can be purchased in blocks by an Internet Service Provider (ISP) and assigned dynamically to computers as they connect to the Internet. - The Transmission Control Protocol (TCP) controls the method by which messages are broken down into packets and then reassembled when they reach their final destination. The Internet Protocol (IP) is concerned with labeling the packets for delivery and controlling the packets' paths from sender to recipient.
- A router is a special-purpose computer that receives and forwards packets across the Internet, guided by IP labeling.
- When a computer specifies a domain name (e.g.,
www.creighton.edu) in an email or Web address, that domain name is converted into the corresponding IP address by a domain name server.
Review Questions
- The Internet of today evolved from the ARPANET of the 1960s and 70s. In what ways is the Internet similar to the old ARPANET? In what ways is it different?
- The Internet is often described as the "Information Superhighway." Describe how the analogy of a highway system fits the structure of the Internet.
- Describe the role of the Internet Society in managing the technical aspects and growth of the Internet.
- FIGURE 5 documents the growth of the Internet over three decades. After astounding growth in the 1980s and 1990s, the increase in number of computers on the Internet slowed considerably in the 2000s. Do these numbers imply that the Internet became less popular in the 2000s? If not, what explains these numbers?
- What is meant by the term Internet of Things? How is the Internet of Things from the 2010s different from the Internet of the 2000s?
- Paul Baran proposed two groundbreaking design ideas for the structure and behavior of the ARPANET. Describe these design ideas and the benefits they provide.
- Describe how packet switching can increase the reliability of a network.
- Internet communications are defined by a set of protocols called TCP/IP. What do TCP and IP stand for, and what is the role of each protocol in transmitting and receiving information?
- The common use of the term "protocol" refers to a system of rules governing affairs of state or diplomacy. How are Internet protocols, TCP and IP, similar to diplomatic protocols? How are they different?
- What is an IP address? What steps are involved in mapping a computer's domain name (e.g., www.creighton.edu) to its IP address?